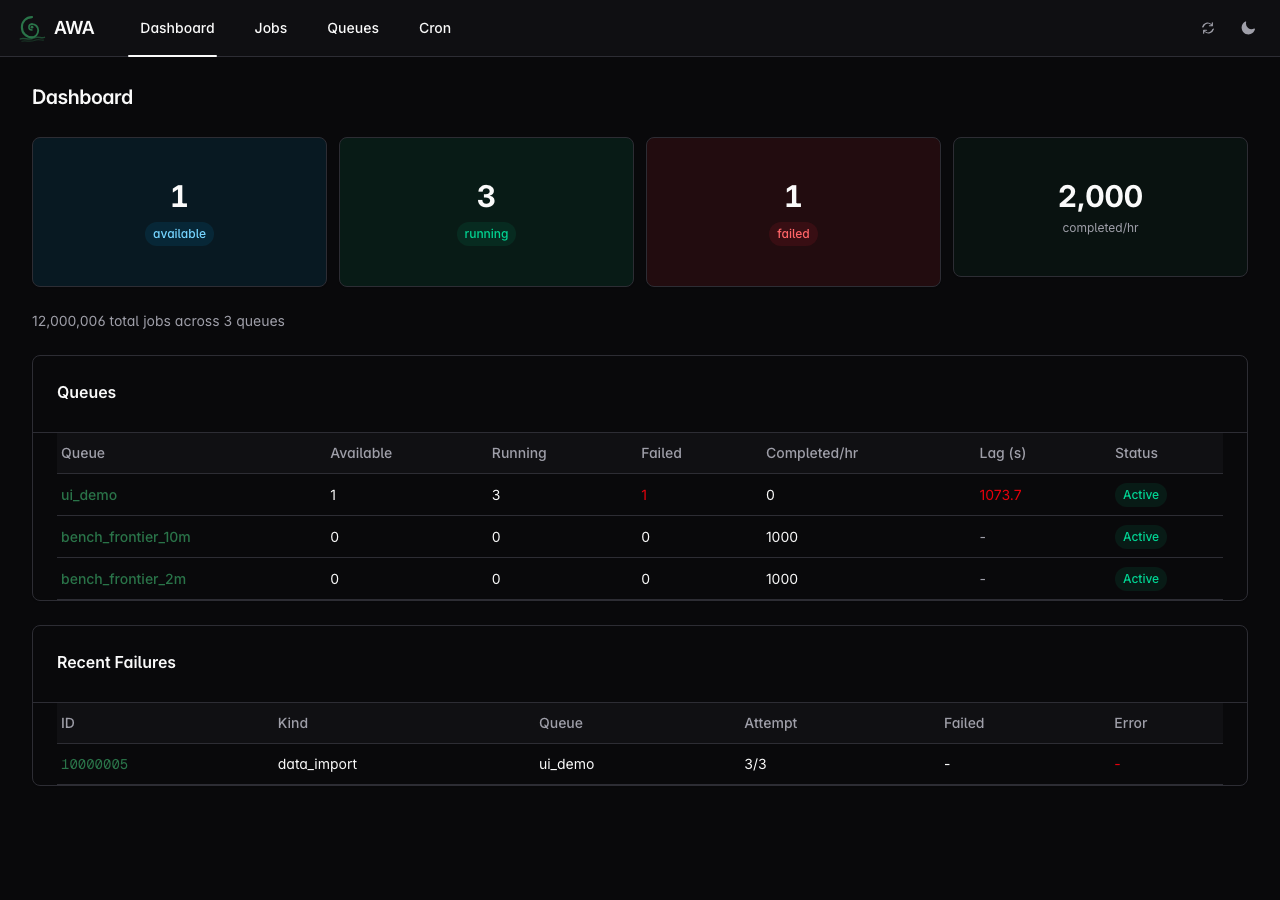
Postgres-native job queue for Rust and Python.
Awa (Māori: river) fills the gap between Postgres event queues that are too narrow for real job-queue behavior and language-specific job frameworks (River, Oban, Sidekiq) that couple you to one ecosystem. If you run Rust or Python (or both) on Postgres and want priorities, cron, DLQ, and transactional enqueue without Redis or RabbitMQ, Awa is built for you.
- Transactional enqueue — insert jobs inside your business transaction. Commit = visible. Rollback = gone.
- Unique jobs — declare uniqueness by kind/queue/args; cancel by unique key without storing job IDs.
- Priorities, retries, snoozes — exponential backoff with jitter; priority aging for fairness.
- Dead Letter Queue — first-class DLQ with per-queue opt-in, retention, and operator retry/purge.
- Periodic/cron jobs — leader-elected scheduler with timezone support, atomic enqueue, and per-schedule pause/resume.
- Sequential callbacks —
wait_for_callback()/resume_external()for multi-step orchestration within a single handler. - Webhook callbacks — park jobs for external completion with optional CEL-expression filtering.
- Rust and Python workers — same queues, same storage engine, mixed deployments.
- Crash recovery — heartbeat + hard deadline rescue. Stale jobs recovered automatically.
- Runtime-owned maintenance — dispatch, rescue, queue/lease/claim ring rotation, pruning, and cleanup run in the worker fleet; no
pg_cronticker required. - Segmented queue storage — append-only ready/terminal partitions, rotating lease and receipt rings, and separate deferred/DLQ tables keep queue history and execution churn off the dispatch path.
- LISTEN/NOTIFY wakeup — millisecond-scale pickup latency.
- HTTP Worker — feature-gated worker that dispatches jobs to serverless functions (Lambda, Cloud Run) via HTTP with BLAKE3-signed callback auth.
- Weighted concurrency + rate limiting — global worker pool with per-queue guarantees; per-queue token bucket.
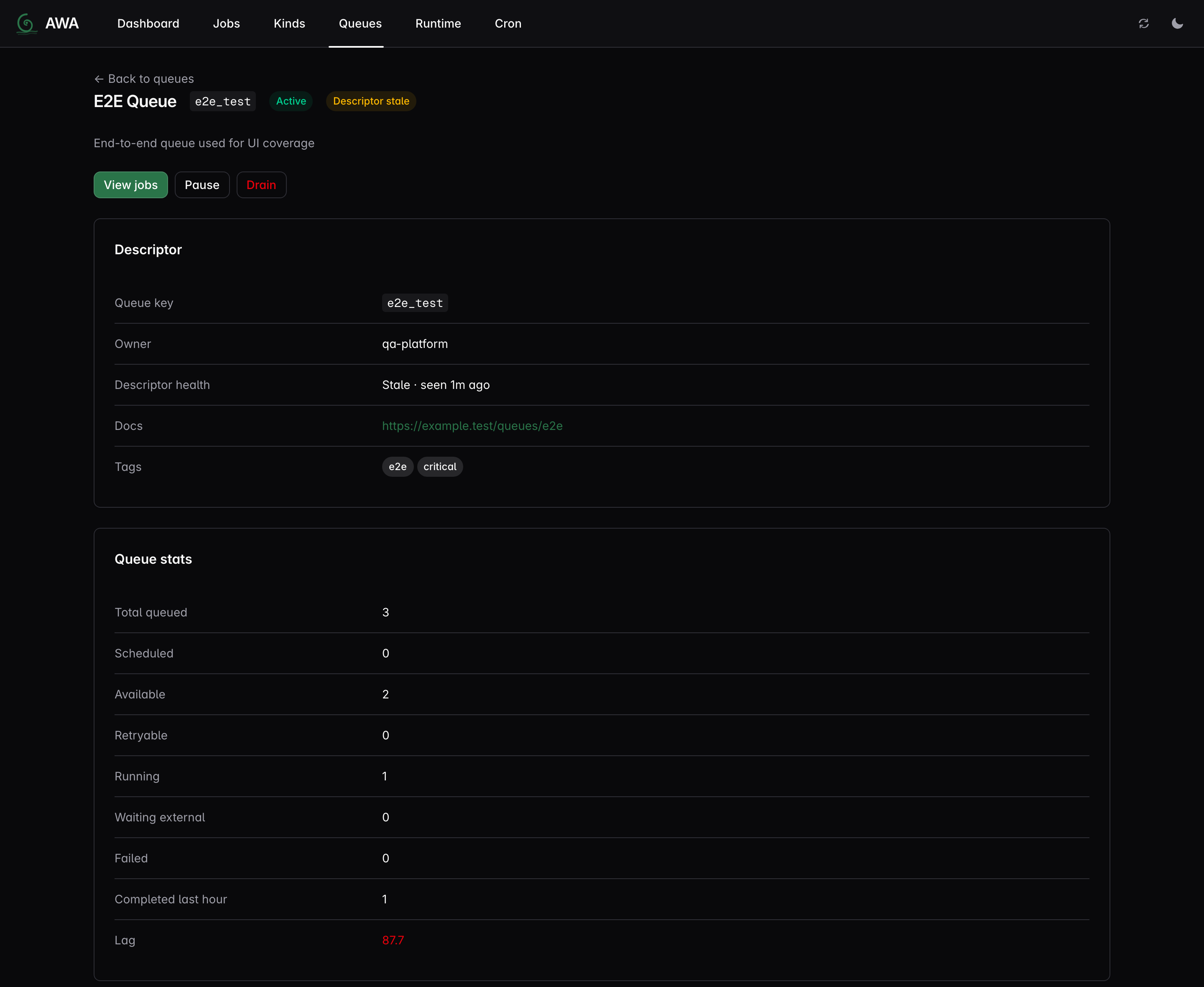
- Web UI — dashboard, job inspector, queue management, cron controls, DLQ retry/purge.
- Structured progress — handlers report percent, message, and checkpoint metadata; persisted across retries.
- OpenTelemetry metrics — 20+ built-in counters, histograms, and gauges for Prometheus/Grafana. Python workers enable export with
awa.init_telemetry(endpoint, service); Rust workers install their own provider. - Operator descriptors — code-declared queue and job-kind names/descriptions with stale/drift visibility in the UI.
- Postgres-only — one dependency you already have; no Redis, no RabbitMQ, no separate scheduler.
Core concurrency invariants — no duplicate processing after rescue, stale completions rejected, no claim/rotate/prune deadlock, DLQ round-trip safety, prune-segment emptiness, heartbeat-driven short-job rescue — are checked by TLA+ models covering the segmented storage engine, the lock-ordering protocol, and the single/multi-instance worker runtime. The storage model has a trace-replay harness that verifies concrete runtime-test event sequences against the spec.
- Transactional enqueue is a core Postgres-native feature: enqueue inside the same transaction as application data, and the job commits or rolls back with that data.
- At-least-once delivery is the contract. Awa rejects stale completions and rescues stuck work, but it does not promise “exactly once”.
- Idempotency is recommended for handlers, because retries and recovery are part of the honest failure model.
- No lost work under failure takes priority over clever fast paths. If a design weakens crash/restart safety, it loses even if the benchmark looks better.
- Strict FIFO per
(queue, priority)by default. Operators can opt a contended queue into partitioned FIFO by raisingawa.queue_meta.enqueue_shards— the same kind of trade as choosing SQS Standard over SQS FIFO, or raising Kafka partition count. Producers pin related jobs to one shard withordering_key. See ADR-025.
The north-star benchmark is not enqueue-only speed. Awa is judged by end-to-end completion throughput, p99 end-to-end latency, queue depth under oversupply, WAL bytes per completed job, transaction commits per completed job, and dead tuples / prune lag. Enqueue-only rates are reported separately for producer-path regressions.
Queue-storage soak reference, 5k-job runtime run: 9.5k jobs/s, 22 ms p95 pickup, 417 exact final dead tuples. Enqueue reference: ~30k/s single-producer, ~100k/s multi-producer.
For high-volume queue-storage producers, use the direct queue-storage COPY
path: Python enqueue_many_copy() or Rust
QueueStorage::enqueue_params_copy(). Configure direct-copy producers with the
same queue-storage routing knobs as the worker fleet, especially
queue_stripe_count / queue_storage_queue_stripe_count. The older
insert_many_copy() API is the compatibility insert surface; it remains useful
for canonical-storage compatibility and adapters, but it is not the
queue-storage producer fast path.
A phase-driven portable benchmark harness comparing Awa against pgque, procrastinate, pg-boss, river, oban, and pgmq on a shared Postgres instance lives in its own repository: hardbyte/postgresql-job-queue-benchmarking. It records producer, subscriber, and end-to-end delivery latency alongside throughput, queue depth, dead tuples, WAL pressure, and transaction pressure over time.
Methodology and caveats live in benchmarking notes. Validation artifacts: ADR-019 (queue storage) and ADR-023 (receipt-plane ring partitioning).
Awa is for teams that already trust Postgres and want a real job queue, not just a stream or a framework tied to one host language.
- Choose Awa when you want priorities, unique jobs, retries, cron, callbacks, DLQ, and operator tooling on one Postgres-backed runtime.
- Choose PgQue-style systems when you want an event queue with independent consumer cursors and event-log semantics first.
- Choose River or Oban Pro when you want a job framework tightly shaped around one surrounding language ecosystem.
See docs/positioning.md for the category map and messaging guidance.
# 1. Install
pip install 'awa-pg[ui]' # Python SDK + dashboard binary
# pip install awa-pg # SDK only (no dashboard, smaller wheel)
# or: cargo add awa # Rust
# 2. Start Postgres and run migrations
awa --database-url $DATABASE_URL migrate
# 3. Write a worker and start processing (see examples below)
# 4. Monitor
awa --database-url $DATABASE_URL serve # → http://127.0.0.1:3000
awa --database-url $DATABASE_URL storage status
awa --database-url $DATABASE_URL job dump 123
awa --database-url $DATABASE_URL job dump-run 123The Awa mental model: your app inserts durable queue entries inside Postgres,
often in the same transaction as business data; workers claim runnable entries
through short-lived execution leases and rescue stale work after crashes;
long-running attempts touch attempt_state only when they need mutable data
like progress or callback state; operators inspect live, terminal, and DLQ
state through the CLI or the built-in UI.
Language-specific guides:
Configuring real workloads:
- Worker scope: which queues and which kinds — running a worker against one queue, or splitting kinds across queues
- Job priority and aging — priority scale, escalation, the per-queue
priority_aging_interval - Reliability timings — heartbeat / deadline / callback rescue, retention, the 3× heartbeat-staleness rule
- Dead Letter Queue — when to enable, per-queue overrides, operator workflow
- Deploying on managed Postgres — Cloud SQL / AlloyDB sizing data, IAM grants, auth-proxy sidecar, gotchas
Already running 0.5? Read the 0.5 → 0.6 upgrade guide before you bump — 0.6 introduces a staged storage transition (canonical → prepared → mixed_transition → active) with a refused-by-default gate that expects the operator to roll out queue-storage-capable workers first.
import awa
import asyncio
from dataclasses import dataclass
@dataclass
class SendEmail:
to: str
subject: str
async def main():
client = awa.AsyncClient("postgres://localhost/mydb")
await client.migrate()
@client.task(SendEmail, queue="email")
async def handle_email(job):
print(f"Sending to {job.args.to}: {job.args.subject}")
await client.start([("email", 2)])
await client.insert(
SendEmail(to="alice@example.com", subject="Welcome"),
queue="email",
)
await asyncio.sleep(1)
await client.shutdown()
asyncio.run(main())Progress tracking — checkpoint and resume on retry:
@client.task(BatchImport, queue="etl")
async def handle_import(job):
last_id = (job.progress or {}).get("metadata", {}).get("last_id", 0)
for item in fetch_items(after=last_id):
process(item)
job.set_progress(50, "halfway")
job.update_metadata({"last_id": item.id})
await job.flush_progress()Transactional enqueue — atomic with your business logic:
from awa.bridge import insert_job
from sqlalchemy import text
from sqlalchemy.ext.asyncio import AsyncSession
async def create_order(session: AsyncSession, order_id: str) -> int:
async with session.begin():
await session.execute(
text("INSERT INTO orders (id) VALUES (:order_id)"),
{"order_id": order_id},
)
job = await insert_job(
session,
SendEmail(to="alice@example.com", subject="Order confirmed"),
queue="email",
)
return job["id"]AsyncClient is the worker/admin/direct-producer handle. In web handlers,
keep using SQLAlchemy, asyncpg, psycopg, Django, or your existing database
stack, and call awa.bridge.insert_job(...) inside that transaction.
Sync API for synchronous workers/admin code:
client = awa.Client("postgres://localhost/mydb")
client.migrate()
job = client.insert(SendEmail(to="bob@example.com", subject="Hello"))For Django/Flask request transactions, use awa.bridge.insert_job_sync(...)
with the framework's existing connection/session instead of routing app SQL
through Awa.
Sequential callbacks — suspend a handler, wait for an external system, then resume:
@client.task(ProcessPayment, queue="payments")
async def handle_payment(job):
token = await job.register_callback(timeout_seconds=3600)
send_to_payment_gateway(token.id, job.args.amount)
result = await job.wait_for_callback(token)
# result contains the payload from resume_external()
await record_payment(job.args.order_id, result)The external system calls await client.resume_external(callback_id, {"status": "paid"}) to wake the handler.
Periodic jobs — leader-elected cron scheduling with timezone support:
client.periodic(
"daily_report", "0 9 * * *",
GenerateReport, GenerateReport(format="pdf"),
timezone="Pacific/Auckland",
# missed_fire_policy="coalesce" by default; use "catch_up" for
# idempotent reconciliation jobs that need every missed fire.
)6-field expressions with seconds precision are also supported: "*/15 * * * * *" fires every 15 seconds.
See examples/python/ for complete runnable scripts tested in CI.
use awa::{Client, QueueConfig, JobArgs, JobResult, JobError, JobContext, Worker};
use serde::{Serialize, Deserialize};
#[derive(Debug, Serialize, Deserialize, JobArgs)]
struct SendEmail {
to: String,
subject: String,
}
struct SendEmailWorker;
#[async_trait::async_trait]
impl Worker for SendEmailWorker {
fn kind(&self) -> &'static str { "send_email" }
async fn perform(&self, ctx: &JobContext) -> Result<JobResult, JobError> {
let args: SendEmail = serde_json::from_value(ctx.job.args.clone())
.map_err(|e| JobError::terminal(e.to_string()))?;
send_email(&args.to, &args.subject).await
.map_err(JobError::retryable)?;
Ok(JobResult::Completed)
}
}
// Start workers with a typed lifecycle hook
let client = Client::builder(pool.clone())
.queue("default", QueueConfig::default())
.register_worker(SendEmailWorker)
.on_event::<SendEmail, _, _>(|event| async move {
if let awa::JobEvent::Exhausted { args, error, .. } = event {
tracing::error!(to = %args.to, error = %error, "email job exhausted retries");
}
})
.build()?;
client.start().await?;
// Use your application's sqlx transaction for app rows and Awa jobs.
let mut tx = pool.begin().await?;
sqlx::query("INSERT INTO orders (id) VALUES ($1)")
.bind(order_id)
.execute(&mut *tx)
.await?;
awa::insert_with(
&mut *tx,
&SendEmail { to: "alice@example.com".into(), subject: "Welcome".into() },
awa::InsertOpts {
unique: Some(awa::UniqueOpts { by_args: true, ..Default::default() }),
..Default::default()
},
).await?;
tx.commit().await?;
// Cancel by unique key (e.g., when the triggering condition is resolved)
awa::admin::cancel_by_unique_key(&pool, "send_email", None, Some(&serde_json::json!({"to": "alice@example.com", "subject": "Welcome"})), None).await?;Lifecycle hooks receive Started after a claim commits as the worker handler
is about to run, plus outcome events (Completed, Retried, Exhausted,
Cancelled) after the corresponding state transition commits. Hooks run in
detached tasks, so they do not block job execution.
Cancellation is cooperative for running handlers:
- Rust handlers can poll
ctx.is_cancelled(). - Python handlers can poll
job.is_cancelled(). - Shutdown and runtime rescue paths flip that flag.
- Admin cancel (
awa::admin::cancel,client.cancel) updates job state in storage and signals the matching in-flight handler, when that exact running attempt is still alive on a worker process. - If a handler ignores the signal or returns too late, stale completion/retry results remain no-ops because the job is already cancelled in storage.
pip install awa-pg # SDK: insert, worker, admin, progress
pip install 'awa-pg[ui]' # SDK + bundled `awa` binary for the dashboard
# or, just the CLI:
pip install awa-cli # CLI on its own: migrations, queue admin, web UIpip install awa-pg stays small for workers and producers. The [ui] extra
pulls in awa-cli, which ships the
awa binary plus the embedded React dashboard; afterwards python -m awa serve (or awa serve directly) launches it.
[dependencies]
awa = "0.6"Available via pip (no Rust toolchain needed) or cargo:
pip install awa-cli
# or: cargo install awa-cli
awa --database-url $DATABASE_URL migrate
awa --database-url $DATABASE_URL serve
awa --database-url $DATABASE_URL queue stats
awa --database-url $DATABASE_URL job list --state failed
awa --database-url $DATABASE_URL job dump 123
awa --database-url $DATABASE_URL job dump-run 123 ┌────────────────┐ ┌────────────────┐
│ Rust producer │ │ Python (pip) │
└───────┬────────┘ └────────┬───────┘
└────────┬───────────┘
▼
┌──────────────────────────────┐
│ PostgreSQL │
│ ready / deferred entries │
│ active leases / attempt_state│
│ terminal / dlq entries │
└──────────────┬───────────────┘
│
┌─────────┼─────────┐
▼ ▼ ▼
┌────────┐┌────────┐┌────────┐
│ Worker ││ Worker ││ Worker │
│ (Rust) ││ (PyO3) ││ (PyO3) │
└────────┘└────────┘└────────┘
All coordination through Postgres. The Rust runtime owns dispatch, leases, heartbeats, rescue, rotation, prune, and shutdown for both languages. Mixed Rust and Python workers coexist on the same queues. See architecture overview for full details.
| Crate | Purpose |
|---|---|
awa |
Main crate — re-exports awa-model + awa-worker |
awa-model |
Types, queries, migrations, admin ops |
awa-macros |
#[derive(JobArgs)] proc macro |
awa-worker |
Runtime: dispatch, heartbeat, maintenance |
awa-ui |
Web UI (axum API + embedded React frontend) |
awa-cli |
CLI binary (migrations, admin, serve) |
awa-python |
PyO3 extension module (pip install awa-pg) |
awa-testing |
Test helpers (TestClient) |
| Doc | Description |
|---|---|
| Rust getting started | From cargo add to a job reaching completed |
| Python getting started | From pip install to a job reaching completed |
| Deployment guide | Docker, Kubernetes, pool sizing, graceful shutdown |
| Migration guide | Fresh installs, upgrades, extracted SQL, rollback strategy |
| 0.5 → 0.6 upgrade | Step-by-step operator checklist for the staged storage transition |
| Configuration reference | QueueConfig, ClientBuilder, Python start(), env vars |
| HTTP workers and callbacks | Serverless dispatch, callback receiver endpoints, signature verification |
| Lifecycle hooks | React to job start/finish/retry/callback events for metrics, alerting, cleanup |
| Security & Postgres roles | Minimum-privilege roles, callback auth, operational guidance |
| Troubleshooting | Stuck running jobs, leader delays, heartbeat timeouts |
| Architecture overview | System design, data flow, state machine, crash recovery |
| Web UI design | API endpoints, pages, component library |
| Benchmarking notes | Methodology, headline numbers, how to run |
| Validation test plan | Full test matrix with 100+ test cases |
| TLA+ correctness models | Formal verification of core invariants |
| Grafana dashboards | Pre-built Prometheus dashboards for monitoring |
Architecture Decision Records (ADRs)
- 001: Postgres-only
- 002: BLAKE3 uniqueness
- 003: Heartbeat + deadline hybrid
- 004: PyO3 async bridge
- 005: Priority aging
- 006: AwaTransaction as narrow SQL surface
- 007: Periodic cron jobs
- 008: COPY batch ingestion
- 009: Python sync support
- 010: Per-queue rate limiting
- 011: Weighted concurrency
- 012: Split hot and deferred job storage
- 013: Durable run leases and guarded finalization
- 014: Structured progress and metadata
- 015: Builder-side lifecycle hooks
- 016: Public Rust Postgres enqueue adapter API
- 017: Python insert-only transaction bridging
- 018: HTTP Worker for serverless job dispatch
- 019: Queue Storage Engine
- 020: Dead Letter Queue
- 021: Sequential callbacks and callback heartbeats
- 022: Descriptor catalog
- 023: Receipt plane ring partitioning
See docs/adr/README.md for the index with status and supersession.
MIT OR Apache-2.0