Home • Web Platform • Installing • Web Application • How To Use • Trained Models • Citation
⭐ 2025 Google PhD Fellowship in Health Research awarded to support outstanding and innovative research in computer science and related fields, providing total funding of USD 30.000 over two years — [Link]
⭐ ISME Scholar Mobility Fund awarded with funding of € 2.300 for a research period in July 2026 at the Helmholtz Centre for Environmental Research (UFZ) in Leipzig, Germany
The prediction of biological sequence properties has traditionally relied on alignment-based methods that assume evolutionary homology and depend on curated reference databases. This, in turn, limits scalability and sensitivity for large or heterogeneous datasets, remote homologs, short sequences, and rapidly evolving genomic regions. Although Machine-Learning (ML) approaches offer alignment-free alternatives, their broader adoption is limited by: (i) the lack of standardized, externally validated benchmark models across diverse datasets, and (ii) the technical expertise required for feature engineering, model selection, and evaluation. Automated machine learning (AutoML) alleviates these challenges by systematically optimizing representations and models with minimal user intervention. However, most existing frameworks prioritize task-specific model construction and lack mechanisms for preserving trained models as persistent, comparable benchmarks. We introduce BioAutoML-FAST, an end-to-end web platform for automated ML analysis of nucleotide and amino acid sequences. It supports both classification and regression tasks and automates feature extraction, model training, and evaluation without requiring prior user expertise. Uniquely, it serves as a community benchmarking resource, hosting a continuously expanding repository of reusable, standardized models (currently 60) for genomic, transcriptomic, and proteomic applications. Extensive validation on independent datasets demonstrates performance comparable to or exceeding that of state-of-the-art methods, including protein language models such as ESM-2. BioAutoML-FAST is available at https://bioautoml.icmc.usp.br/. This website is free and open to all users, and there is no login requirement.
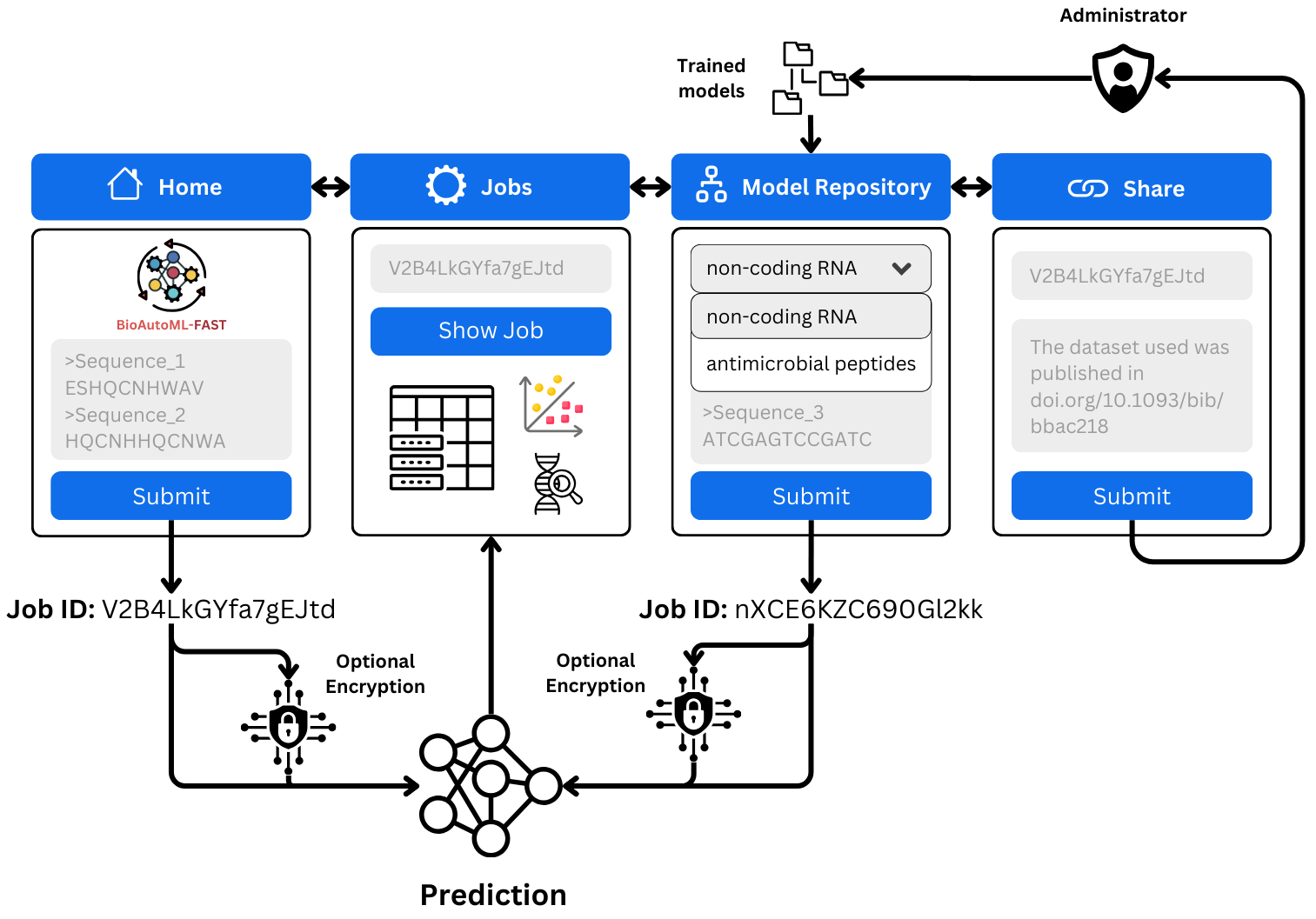
- Alignment-free machine learning for nucleotide and amino acid sequences
- Automated feature engineering — Bayesian optimization (Optuna) selects the best descriptor combination from a pool of 20 nucleotide descriptors and 23 protein descriptors
- Automated model training and hyperparameter optimization — supports LightGBM, XGBoost, and Random Forest with Optuna-driven tuning
- Classification and regression — binary, multiclass, and quantitative prediction tasks
- Structured data support —
generation.pycan be used directly with pre-computed feature matrices (CSV), without FASTA input - Pre-trained model repository — 60+ community benchmarks spanning genomics, transcriptomics, and proteomics, browsable on the web platform
- Reusable models — trained models can be saved and re-applied to new sequences for prediction
- Web platform — hosted at bioautoml.icmc.usp.br, no login required; can also be self-hosted
-
Breno L. S. de Almeida, Robson P. Bonidia, Martin Bole, Anderson P. Avila-Santos, Peter F. Stadler, Ulisses Rocha, André C. P. L. F. de Carvalho
-
Correspondence: brenoslivio@usp.br, bonidia@utfpr.edu.br or ulisses.rocha@ufz.de
Silva de Almeida, B. L., Bonidia, R., Bole, M., Avila-Santos, A., Stadler, P. F., Nunes da Rocha, U., & de Carvalho, A. C. L. F. (2026). BioAutoML-FAST: an automated machine-learning platform for reusable and benchmarked biological sequence models. bioRxiv, 2026-04. DOI
If you want to use BioAutoML-FAST locally you can clone the repository and add the necessary submodules:
git clone https://github.com/Bonidia/BioAutoML-FAST.git BioAutoML-FAST
cd BioAutoML-FAST
git submodule init
git submodule update1 - Install uv
If using Linux or Mac:
curl -LsSf https://astral.sh/uv/install.sh | shIf using Windows, use irm to download the script and execute it with iex:
powershell -ExecutionPolicy ByPass -c "irm https://astral.sh/uv/install.ps1 | iex"2 - Preparing the virtual environment
With uv installed, inside the folder use following command to synchronize the virtual environment with the necessary dependencies:
uv sync3 - Activate environment
After preparing the environment, you can activate the environment on Linux or Mac with:
source .venv/bin/activateUsing Windows:
.venv\Scripts\activate4 - Deactivate environment
You can deactivate the environment using:
deactivateThe hosted platform is freely available at https://bioautoml.icmc.usp.br/ — no login required.
If you prefer to run the web application locally or deploy it on your own server, follow the steps below.
The web app uses Streamlit for the interface and Redis + RQ to handle background jobs. Make sure Redis is installed and running before starting the app:
# Ubuntu/Debian
sudo apt install redis-server
sudo systemctl start redis-server
# macOS (Homebrew)
brew install redis
brew services start redisWith the virtual environment activated and Redis running, open two separate terminals from the repository root:
Terminal 1 — start the RQ worker:
cd App
rq worker bioautomlTerminal 2 — start the Streamlit server:
cd App
streamlit run app.pyThe app will be available at http://localhost:8501 by default.
For a persistent server deployment, you can use the provided systemd service files located in App/services/. Copy them to your systemd directory and enable them:
sudo cp App/services/bioautoml-web.service /etc/systemd/system/
sudo cp App/services/bioautoml-worker.service /etc/systemd/system/
sudo systemctl daemon-reload
sudo systemctl enable bioautoml-web bioautoml-worker
sudo systemctl start bioautoml-web bioautoml-workerBioAutoML-FAST uses a two-step pipeline: engineering.py handles feature extraction and descriptor selection, then automatically invokes generation.py for model training and hyperparameter optimization.
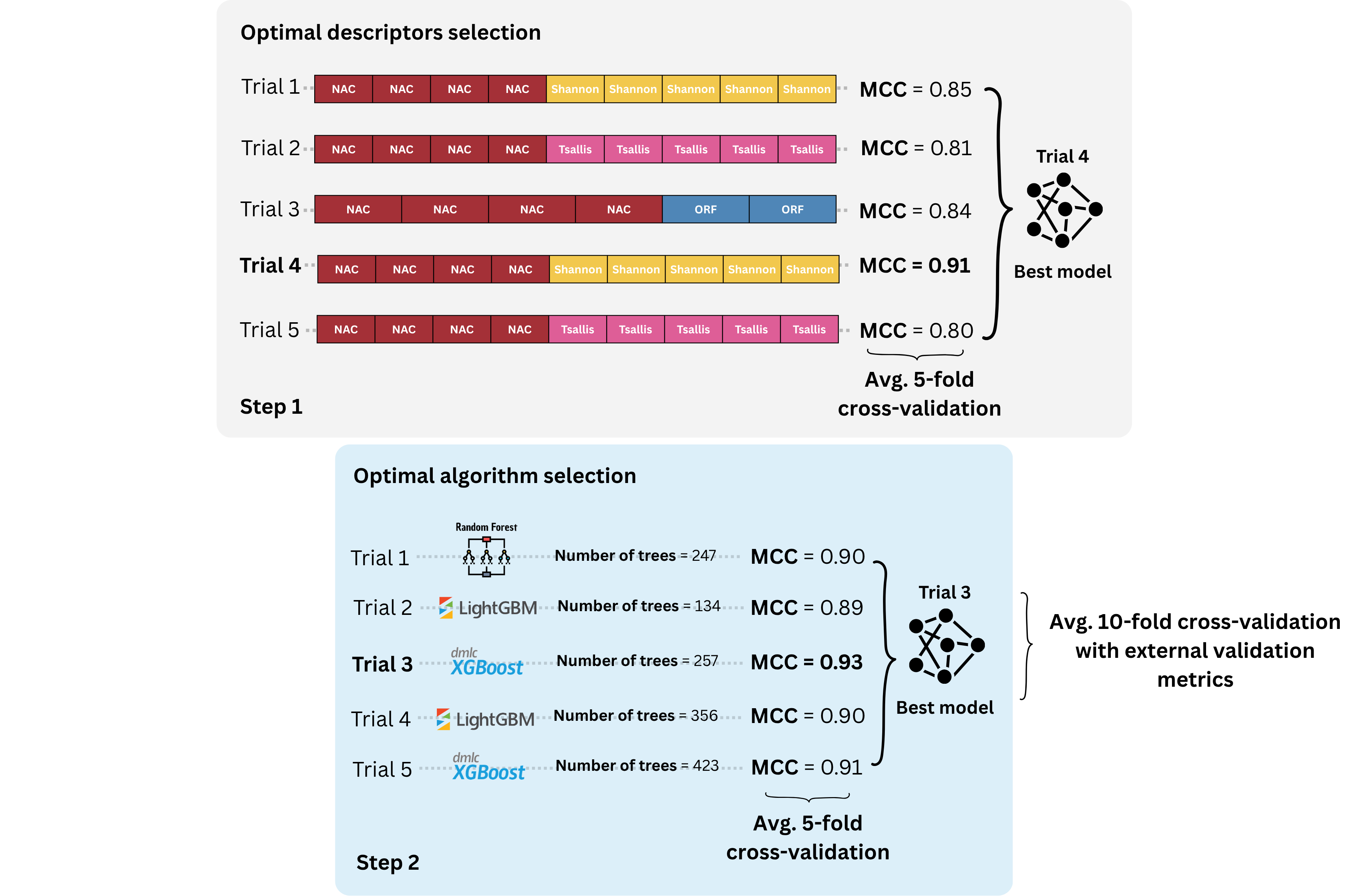
The engineering.py script performs the first step of BioAutoML-FAST. It extracts sequence descriptors from the input FASTA files, performs automated feature engineering/descriptor selection, and then automatically calls generation.py for model generation and hyperparameter optimization.
| Option | Description | Default |
|---|---|---|
-fasta_train, --fasta_train |
One or more training FASTA files. | Required |
-fasta_label_train, --fasta_label_train |
Labels associated with each training FASTA file. The order must match -fasta_train. |
Required |
-fasta_test, --fasta_test |
One or more testing FASTA files. | Optional |
-fasta_label_test, --fasta_label_test |
Labels associated with each testing FASTA file. The order must match -fasta_test. |
Optional |
-dtype, --dtype |
Type of input data. Supported values: DNA/RNA or Protein. |
DNA/RNA |
-task, --task |
Machine learning task. Use 0 for classification and 1 for regression. |
0 |
-estimations, --estimations |
Number of estimations used during automated feature engineering. | 200 |
-patience, --patience |
Number of trials without improvement before early stopping. | 80 |
-tuning, --tuning |
Number of trials used for hyperparameter optimization in generation.py. |
150 |
-difference, --difference |
Minimum improvement required before early stopping. | 0.001 |
-n_cpu, --n_cpu |
Number of CPU cores to use. Use -1 to use all available cores. |
-1 |
-output, --output |
Output directory where results will be saved. | Required |
python engineering.py \
-fasta_train train/ncRNA.fasta train/lncRNA.fasta train/circRNA.fasta \
-fasta_label_train ncRNA lncRNA circRNA \
-fasta_test test/ncRNA.fasta test/lncRNA.fasta test/circRNA.fasta \
-fasta_label_test ncRNA lncRNA circRNA \
-dtype DNA/RNA \
-task 0 \
-output resultspython engineering.py \
-fasta_train train/enzyme.fasta \
-fasta_label_train enzyme \
-fasta_test test/enzyme.fasta \
-fasta_label_test enzyme \
-dtype Protein \
-task 1 \
-output resultsThe generation.py script performs the second step of BioAutoML-FAST. It trains and optimizes machine learning models using the descriptors generated during the feature engineering step. The module supports both classification and regression tasks, including hyperparameter optimization and external test evaluation.
Structured data:
generation.pycan also be used as a standalone script with any pre-computed feature matrix in CSV format — no FASTA input or feature extraction required. This makes it suitable for general tabular ML tasks beyond biological sequences.
| Option | Description | Default |
|---|---|---|
-path_model, --path_model |
Path to a previously trained model to be reused for prediction or evaluation. | '' |
-task, --task |
Machine learning task. Use 0 for classification and 1 for regression. |
0 |
-tuning, --tuning |
Number of hyperparameter optimization trials. | 150 |
-train, --train |
Training feature matrix in CSV format. | Required |
-train_label, --train_label |
Training labels in CSV format. | Required |
-train_nameseq, --train_nameseq |
CSV file containing sequence names/identifiers for the training set. | Required |
-test, --test |
Test feature matrix in CSV format. | Optional |
-test_label, --test_label |
Test labels in CSV format. | Optional |
-test_nameseq, --test_nameseq |
CSV file containing sequence names/identifiers for the test set. | Optional |
-n_cpu, --n_cpu |
Number of CPU cores to use. Use -1 to use all available cores. |
-1 |
-output, --output |
Output directory where models and results will be saved. | Required |
Both scripts write results to the directory specified by -output. Typical outputs include:
| File | Description |
|---|---|
trained_model.sav |
Serialized model (joblib) — reusable for prediction on new sequences |
training_kfold(10)_metrics.csv |
10-fold cross-validation metrics on the training set |
training_confusion_matrix.csv |
Confusion matrix for the training set (classification only) |
metrics_test.csv |
Evaluation metrics on the held-out test set |
test_confusion_matrix.csv |
Confusion matrix for the test set (classification only) |
test_predictions.csv |
Per-sequence predictions on the test set |
feature_importance.tsv |
Feature importance scores |
best_descriptors/ |
Best-selected descriptor matrices for train and test sets |
The platform hosts a continuously expanding repository of pre-trained, benchmarked models for genomic, transcriptomic, and proteomic applications. You can browse and use these models directly through the web platform at https://bioautoml.icmc.usp.br/.
To download all trained models for offline use, they are available on Zenodo:
https://doi.org/10.5281/zenodo.20349210
If you use this code in a scientific publication, we would appreciate citations to the following paper:
Silva de Almeida, B. L., Bonidia, R., Bole, M., Avila-Santos, A., Stadler, P. F., Nunes da Rocha, U., & de Carvalho, A. C. L. F. (2026). BioAutoML-FAST: an automated machine-learning platform for reusable and benchmarked biological sequence models. bioRxiv, 2026-04. DOI
@article{silva2026bioautoml,
title={BioAutoML-FAST: an automated machine-learning platform for reusable and benchmarked biological sequence models},
author={Silva de Almeida, Breno Livio and Bonidia, Robson and Bole, Martin and Avila-Santos, Anderson and Stadler, Peter F and Nunes da Rocha, Ulisses and de Carvalho, Andre CP L F},
journal={bioRxiv},
pages={2026--04},
year={2026},
publisher={Cold Spring Harbor Laboratory}
}